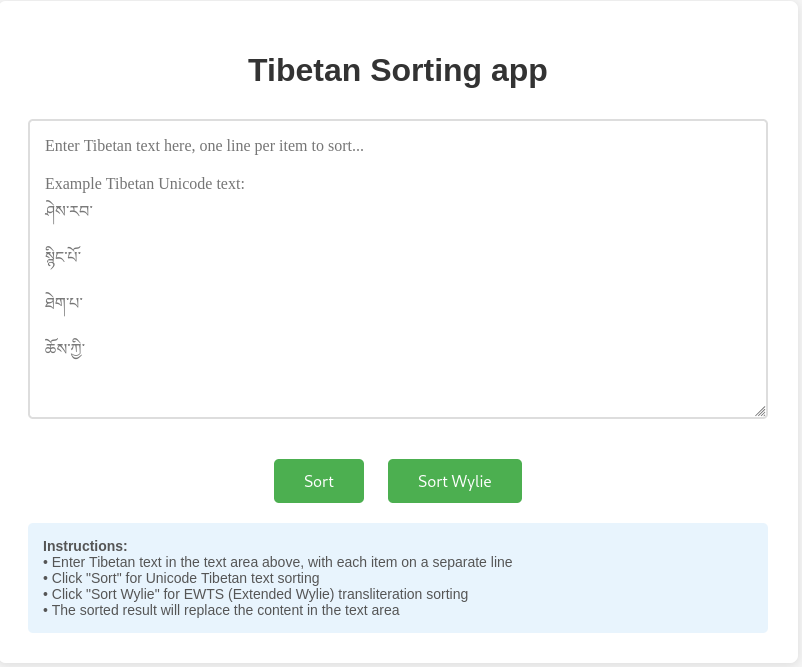
Tibetan Unicode normalization
In this blog post we will document one of the many wonderful technical things developed in the BDRC-MonlamAI OCR project (that resulted in the Tibetan OCR desktop app). Introduction: Tibetan Unicode Normalization? During our experiments with Tibetan encoders for OCR, we created an encoder based on Tibetan stacks. The idea is the make the model “see” the data in a way that is optimal. An intuition we tested is that it would be useful for the model to “see” Tibetan stacks, or glyphs. For instance ...